拓扑感知调度
准备工作
安装 Kueue 0.15.2.
队列设置
按以下配置创建队列:
apiVersion: kueue.x-k8s.io/v1beta2
kind: Topology
metadata:
name: "default"
spec:
levels:
- nodeLabel: "lasyard.io/region"
- nodeLabel: "lasyard.io/rack"
- nodeLabel: "kubernetes.io/hostname"
---
apiVersion: kueue.x-k8s.io/v1beta2
kind: ResourceFlavor
metadata:
name: default
spec:
topologyName: "default"
nodeLabels:
node-group: "tas"
---
apiVersion: kueue.x-k8s.io/v1beta2
kind: ClusterQueue
metadata:
name: test
spec:
namespaceSelector: {} # match all.
resourceGroups:
- coveredResources:
- cpu
- memory
- pods
- nvidia.com/gpu
flavors:
- name: default
resources:
- name: cpu
nominalQuota: 4
- name: memory
nominalQuota: 64Gi
- name: pods
nominalQuota: 4
- name: nvidia.com/gpu
nominalQuota: 24
---
apiVersion: kueue.x-k8s.io/v1beta2
kind: LocalQueue
metadata:
namespace: default
name: test
spec:
clusterQueue: test
通过给节点打标签创建拓扑:
$ kubectl label node --all node-group=tas --overwrite
$ kubectl label node --all lasyard.io/region=region0
$ kubectl label node las0 las1 lasyard.io/rack=rack0
$ kubectl label node las2 las3 lasyard.io/rack=rack1
通过以上标签设置,形成了下图所示的节点拓扑:
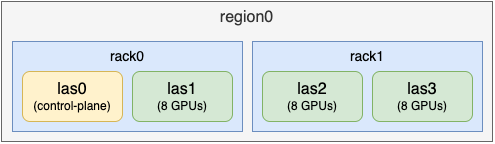
其中 las0 节点为控制平面,实际上不能调度,其他节点都有 8 个 GPU.
强制约束
Job 定义如下:
apiVersion: batch/v1
kind: Job
metadata:
name: tas
labels:
kueue.x-k8s.io/queue-name: test
spec:
completions: 3
completionMode: Indexed
parallelism: 3
template:
metadata:
annotations:
kueue.x-k8s.io/podset-required-topology: "kubernetes.io/hostname"
spec:
restartPolicy: OnFailure
containers:
- image: busybox
imagePullPolicy: IfNotPresent
name: busybox-sleep
command: ["sh", "-c", "trap exit INT TERM; sleep 30s & wait"]
resources:
requests:
cpu: "1"
memory: "100Mi"
nvidia.com/gpu: "4"
limits:
cpu: "1"
memory: "100Mi"
nvidia.com/gpu: "4"
注解 kueue.x-k8s.io/podset-required-topology 将拓扑强制限定为一个节点内。由于总共需要 12 个 GPU, 所以不能在一个节点内调度。
提交 Job 后查看状态:
$ kubectl get job
NAME STATUS COMPLETIONS DURATION AGE
tas Suspended 0/3 5s
由于找不到合适的节点,作业被挂起。修改 Job 定义:
template:
metadata:
annotations:
- kueue.x-k8s.io/podset-required-topology: "kubernetes.io/hostname"
+ kueue.x-k8s.io/podset-required-topology: "lasyard.io/rack"
spec:
restartPolicy: OnFailure
containers:
将拓扑强制限定为同一个 rack 内。重新提交后查看状态:
$ kubectl get job
NAME STATUS COMPLETIONS DURATION AGE
tas Running 0/3 3s 3s
$ kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tas-0-hznsf 1/1 Running 0 12s 192.168.67.130 las2 <none> <none>
tas-1-kpp8s 1/1 Running 0 12s 192.168.67.146 las2 <none> <none>
tas-2-lsnxq 1/1 Running 0 12s 192.168.185.62 las3 <none> <none>
由于 rack0 内实际只有 8 个 GPU, 所以只有在 rack2 内才能调度。
进一步查看 Pod 详情:
$ kubectl desc po tas-2-lsnxq
⋮
QoS Class: Guaranteed
Node-Selectors: kubernetes.io/hostname=las3
node-group=tas
⋮
可见 Kueue 通过将 nodeSelector 指定到节点的方式完全干预了调度。
建议约束
修改 Job 拓扑约束的定义:
template:
metadata:
annotations:
- kueue.x-k8s.io/podset-required-topology: "kubernetes.io/hostname"
+ kueue.x-k8s.io/podset-preferred-topology: "kubernetes.io/hostname"
spec:
restartPolicy: OnFailure
containers:
提交后查看状态:
$ kubectl get job
NAME STATUS COMPLETIONS DURATION AGE
tas Running 0/3 5s 5s
$ kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tas-0-h92nx 1/1 Running 0 11s 192.168.67.150 las2 <none> <none>
tas-1-bdh7v 1/1 Running 0 11s 192.168.67.190 las2 <none> <none>
tas-2-xkqsb 1/1 Running 0 11s 192.168.185.21 las3 <none> <none>
可见约束不满足的情况下会自动放松到上一层级进行适配。为了说明约束仍然生效,将 Pod 的个数减少为 2 个:
labels:
kueue.x-k8s.io/queue-name: test
spec:
- completions: 3
+ completions: 2
completionMode: Indexed
- parallelism: 3
+ parallelism: 2
template:
metadata:
annotations:
这样整个 Job 就可以容纳在一个节点上了。重新提交并查看状态:
$ kubectl get job
NAME STATUS COMPLETIONS DURATION AGE
tas Running 0/2 4s 4s
$ kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tas-0-5dm4g 1/1 Running 0 6s 192.168.221.148 las1 <none> <none>
tas-1-smkf7 1/1 Running 0 6s 192.168.221.162 las1 <none> <none>
无约束
修改拓扑约束定义:
template:
metadata:
annotations:
- kueue.x-k8s.io/podset-required-topology: "kubernetes.io/hostname"
+ kueue.x-k8s.io/podset-unconstrained-topology: "true"
spec:
restartPolicy: OnFailure
containers:
提交后查看状态:
$ kubectl get job
NAME STATUS COMPLETIONS DURATION AGE
tas Running 0/3 2s 2s
$ kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tas-0-lwz24 1/1 Running 0 5s 192.168.221.161 las1 <none> <none>
tas-1-gsmsj 1/1 Running 0 5s 192.168.221.150 las1 <none> <none>
tas-2-g5kdz 1/1 Running 0 5s 192.168.67.138 las2 <none> <none>
默认为无约束。